Error Handling in n8n: Wie Ihre Workflows Fehler selbst abfangen
Ein Workflow laeuft im Test einwandfrei. Dann geht er in Produktion, und nach zwei Wochen faellt auf: Seit drei Tagen kommen keine Ergebnisse mehr. Eine API hat ihr Rate Limit geaendert, ein Token ist abgelaufen, oder der externe Dienst war kurz nicht erreichbar. Niemand hat es bemerkt, weil der Workflow still gestorben ist.
Das ist kein Randfall. Das passiert frueher oder spaeter mit jedem automatisierten Prozess. Die Frage ist nicht ob ein Fehler auftritt, sondern ob Sie davon erfahren, bevor Ihre Kunden es tun.
Warum Error Handling kein Luxus ist
n8n zeigt fehlgeschlagene Executions in der Sidebar rot an. Das hilft, wenn jemand regelmaessig ins Dashboard schaut. Aber das macht in der Praxis niemand taeglich. Und bei Workflows, die im Hintergrund laufen, etwa Datenabgleiche, E-Mail-Weiterleitungen oder API-Synchronisationen, faellt ein stiller Ausfall erst auf, wenn die Folgen sichtbar werden.
Was fehlt, ist ein System, das bei einem Fehler aktiv wird. Das den richtigen Leuten Bescheid gibt, den Fehler dokumentiert und im besten Fall sogar selbst eine Loesung versucht.
Drei Ebenen fuer zuverlaessige Workflows
Error Handling in n8n laesst sich in drei Ebenen aufbauen. Jede Ebene faengt Fehler ab, die durch die vorherige Ebene durchrutschen.
Ebene 1: Retry auf Node-Ebene
Jeder Node in n8n hat eine eingebaute Retry-Funktion. Unter “Settings” laesst sich einstellen, wie oft ein Node bei einem Fehler automatisch wiederholt werden soll und wie lange er dazwischen wartet. Die Obergrenze liegt bei fuenf Versuchen mit maximal fuenf Sekunden Wartezeit.
Fuer API-Aufrufe empfiehlt sich: zwei Wiederholungsversuche mit drei Sekunden Wartezeit. Das reicht, um kurzfristige Netzwerkprobleme oder voruebergehende Serverausfaelle abzufangen, ohne den gesamten Workflow zu blockieren.
Diese Ebene loest die meisten transienten Fehler. Ohne eine einzige Zeile Code.
Ebene 2: Error Output Branch
Manchmal reicht ein Retry nicht. Wenn eine API dauerhaft mit einem 429 (Rate Limit) oder einem 401 (ungueltige Credentials) antwortet, bringt blindes Wiederholen nichts.
Dafuer bietet n8n bei jedem Node drei Optionen unter “On Error”:
| Einstellung | Was passiert |
|---|---|
| Stop Workflow | Standard. Der Workflow stoppt und der Error Workflow wird ausgeloest |
| Continue (Regular Output) | Der Fehler wird als normales Item weitergegeben |
| Continue (Error Output) | Der Fehler wird auf einen separaten zweiten Ausgang geroutet |
Die dritte Option ist die staerkste. Sie ermoeglicht es, fuer jeden einzelnen Node eine eigene Fehlerbehandlung zu bauen. Der erfolgreiche Pfad laeuft normal weiter, der Fehlerpfad kann loggen, benachrichtigen oder einen Fallback ausloesen.
Ein wichtiges Detail: Wenn Sie “Continue (Error Output)” aktivieren, werden die Retry-Einstellungen aus Ebene 1 ignoriert. Sie muessen sich also entscheiden, welche Ebene fuer einen bestimmten Node die richtige ist.
Ebene 3: Error Workflow
Was passiert, wenn ein Fehler durch Ebene 1 und 2 durchrutscht? Dafuer gibt es den Error Workflow. Das ist ein eigenstaendiger Workflow, der automatisch getriggert wird, sobald ein anderer Workflow fehlschlaegt.
Der Aufbau ist einfach:
- Einen neuen Workflow anlegen mit einem “Error Trigger” Node als Startpunkt
- Dahinter die gewuenschte Fehlerbehandlung: E-Mail senden, Slack-Nachricht, oder Daten in eine Datenbank schreiben
- Den Workflow aktivieren
- In jedem anderen Workflow unter Settings den Error Workflow zuweisen
Der Error Trigger liefert automatisch alle relevanten Informationen: welcher Workflow fehlgeschlagen ist, welcher Node den Fehler ausgeloest hat, die Fehlermeldung und einen Link zur betroffenen Execution.
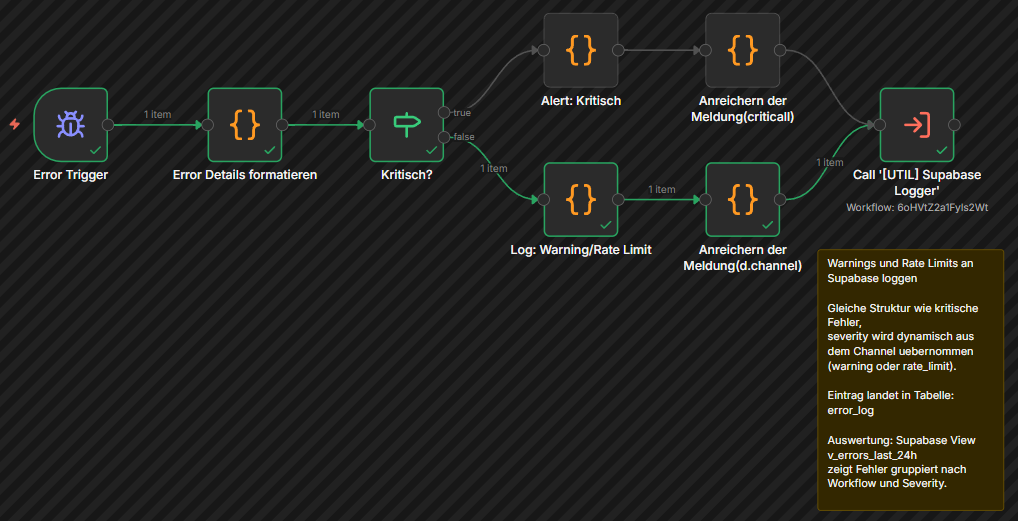
Fehler klassifizieren statt nur weiterleiten
Ein einfacher Error Workflow, der bei jedem Fehler eine E-Mail schickt, ist ein guter Anfang. Aber bei mehreren aktiven Workflows fuellt sich das Postfach schnell. Sinnvoller ist es, Fehler nach Schwere zu unterscheiden.
In der Praxis hat sich eine Dreiteilung bewaehrt:
Kritisch: Authentifizierungsfehler (401, 403), Timeouts und Server-Fehler (500, 502, 503). Hier muss sofort jemand reagieren, denn der Workflow wird ohne Eingriff nicht wieder funktionieren.
Rate Limit: 429-Fehler bedeuten, dass die API zu viele Anfragen erhalten hat. Das loest sich oft von selbst, sollte aber beobachtet werden.
Warnung: Alles andere. Unerwartete Datenformate, fehlende Felder, temporaere Probleme. Wichtig fuer die Fehleranalyse, aber kein Grund fuer naechtliche Alarme.
Ein Code Node im Error Workflow kann die Fehlermeldung analysieren und automatisch die richtige Kategorie zuweisen. Kritische Fehler loesen einen sofortigen Alert aus, Warnungen werden nur protokolliert.
Fehler in Supabase protokollieren
n8n speichert Execution-Logs, aber die Aufbewahrungsdauer ist begrenzt und abhaengig von Ihrer Konfiguration. Fuer eine langfristige Fehleranalyse lohnt es sich, Fehler in eine externe Datenbank zu schreiben. Supabase eignet sich dafuer gut, weil es eine PostgreSQL-Datenbank mit REST-API kombiniert und sich direkt aus n8n ansprechen laesst.
Das Schema
Eine einfache Tabelle reicht fuer den Anfang:
| Spalte | Typ | Zweck |
|---|---|---|
| execution_id | TEXT | Eindeutige ID der fehlgeschlagenen Execution |
| workflow_name | TEXT | Name des betroffenen Workflows |
| node_name | TEXT | Welcher Node den Fehler ausgeloest hat |
| severity | TEXT | Fehler-Kategorie (critical, rate_limit, warning) |
| error_message | TEXT | Die eigentliche Fehlermeldung |
| execution_url | TEXT | Direktlink zur Execution in n8n |
| created_at | TIMESTAMP | Zeitpunkt des Fehlers |
Die Anbindung
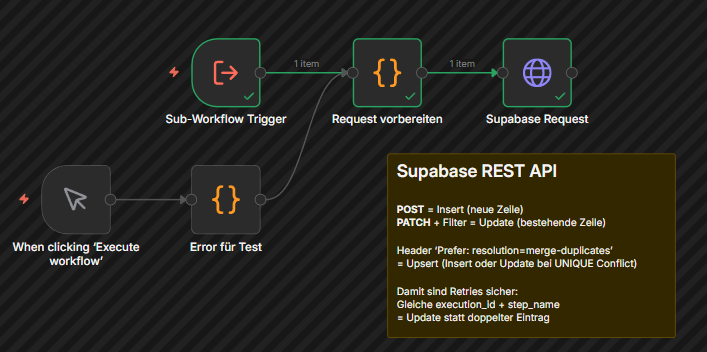
Im Error Workflow wird nach der Fehlerklassifizierung ein HTTP Request Node angehaengt, der die Daten per REST-API an Supabase sendet. Dafuer braucht es nur die Supabase-URL und einen API-Key.
Der Vorteil gegenueber dem eingebauten Supabase Node: Mit einem HTTP Request Node und dem Header “Prefer: resolution=merge-duplicates” koennen Sie Upserts nutzen. Das bedeutet, bei einem Retry wird der bestehende Eintrag aktualisiert statt ein neuer angelegt. Keine Duplikate, auch wenn derselbe Fehler mehrfach auftritt.
Was das bringt
Nach wenigen Wochen haben Sie ein klares Bild:
- Welche Workflows am haeufigsten fehlschlagen
- Ob bestimmte APIs regelmaessig Probleme machen
- Zu welchen Uhrzeiten Fehler gehaeuft auftreten
- Ob die Fehlerrate steigt oder sinkt
Diese Daten sind Gold wert, wenn Sie entscheiden muessen, wo Sie als naechstes optimieren. Statt raten koennen Sie messen.
Fazit
Error Handling macht Workflows nicht fehlerfreier. Aber es macht den Unterschied zwischen “der Workflow ist kaputt und keiner weiss es” und “der Workflow hatte ein Problem und wir wissen genau, was passiert ist”. Drei Ebenen, ein Error Workflow und eine einfache Datenbank-Anbindung. Mehr braucht es nicht, um automatisierte Prozesse produktionsreif abzusichern.
Dieser Beitrag ist Teil meiner n8n-Serie. Im vorherigen Beitrag zeige ich, wie KI-Agents in n8n eingehende Anfragen automatisch bewerten und beantworten.
Sie setzen n8n bereits ein und moechten Ihre Workflows zuverlaessiger machen? Lassen Sie uns gemeinsam schauen, wo Ihre groessten Risiken liegen und wie wir sie absichern.